This part of my work dwells on the application of the support vector machines for building the predictive model using the real world credit data set. I used my own code written in the MATLAB environment with the help of the LIBSVM library [9] that became a standard routines package for the support vector machines during the years thanks to its availability, multi-platform support and continuing optimization. While MATLAB itself contains a built-in support for SVMs, it is not comparably efficient in the sense of the computational time needed.
The data set I used for the research purposes was obtained from the Estonian peer-to-peer lending platform IsePankur.ee/Bondora.com24, that are accessible online thanks to the transparency policy promoted by the platform. [37]
Peer to Peer Lending
Financial sector, despite being one of the most regulated and supervised economic sectors [32], has recently experienced several important and possibly game-changing disruptive innovations like crowdfunding or peer-to-peer lending, among others.
Since peer to peer lending is such a new phenomenon and there are very few peer-reviewed papers studying it from the perspective of the credit scoring, it might be useful to describe its basic principles and examine the common and distinct characteristics of the P2P lending and the traditional banking lending.
I chose Bondora as my data source among other possibilities25 because it’s one of the few platforms that allows foreign investors to participate26 and because I have the personal experience with this platform for more than 15 months at the moment.
While the principles of P2P lending are same, the details of implementation can vary from platform to platform (from country to country). Since these details can influence the credit data collection and the usability of the data set, I will primarily focus on the description of the Bondora specifics and details.
Peer to peer lending (P2P Lending, sometimes also Social Lending) denotes the practice of matching the individual lenders and borrowers for the unsecured consumer loans [24]. This is accomplished with the means of electronic, automatic or semi-automatic, brokers’ systems without traditional intermediaries and thus can be regarded as one of the symptoms of the ongoing disintermediation [6].27
There are 3 main factors that account for the growing popularity of the P2P lending: low barriers, automation and liquidity.
Low barriers: each loan application is divided into small financial amounts and there are usually very low minimum investment requirements. At Bondora, it is possible to invest with as little as €5 in each loan. This implies there are usually hundreds of people financing one loan. And on the other hand it is possible to build a relatively well diversified portfolio of the consumer loans with an amount that is affordable to many non-affluent investors. The operators are regulated by the financial authorities28 and can be therefore considered as an alternative for the individual yield-seeking investors.29
Automation: The proper diversification of one’s investment portfolio can be time-consuming. This is the reason, why all the platforms adopt some form of automation of the investment process. Each platform has some kind of its own internal scoring system, that might not be perfect in the sense of the discrimination power, but its performance is good enough to allow for creating the automatic or semi-automatic investment plans.
An investor sets the level of the maximum riskiness and the minimum interest rate required, optionally sets some other limits30 and these plans then invest small amounts of his total account to each individual loan that meets the criteria. At Bondora, the internal rating consists of an information about disposable income (borrowers are sorted into three categories: A,B,C) and payment history (6 groups: 1000, 900, 800, 700, 600, 500, the higher the better).
The resulting interest rate of the loan is either determined on the auction principle or fixed by the loan applicant or the platform operator. Bondora allowed both of these models in the past.31
In the auction, borrower sets the amount requested and the maximum interest rate he is willing to accept. In the predefined time period, investors then bid the amount and minimum interest rate required. When the time is up and the total amount of bids is at least equal to the amount requested, the loan is assigned to the borrower. The interest rate is determined by the Reverse Auction principle: only the lowest bidding investors are granted the right to finance the loan and interest rate is set as the highest rate that was sufficient to become a financing investor (with respect to the amounts requested by the borrower and offered by the investors).
In the fixed-rate setting, the applicant suggests the interest rate and investors either bid on the loan with some amount of money or pass this opportunity and wait for other loan applications. If enough money is offered by investors, the loan is approved. If not, the borrower can repeat the process with higher interest rate.
From the investor’s point of view, there is a considerable level of automation in the following steps, too. The instalments are automatically credited to investors’ account (proportionally to their amount invested in the loan) as soon as the operator receives the money from the debtor. Automatic remainders are sent in case the borrower is late with his payment.
Default is defined as missing part of the payments by more than 60 days. If default occurs, the whole balance of loan turns into an immediately collectible claim and the operator initiates the debt recovery process using the legal enforcement tools available in the country of the debtor’s residency. The workout process is again fully administered by the operator without any need for the cooperation from the individual investors. The operator is motivated to perform well in this process by two forces. First, he earns part of the recovered money. Second, thanks to the data openness, the global default rates and recovery rates can be monitored on the almost real-time basis. It is in his best interest to keep these numbers low so as not to drive investors out of the market.
Liquidity: With most of the P2P lending platforms, the loans are more or less securitized and the secondary market is established to trade the cash flow claims from the loans among the investors. Bondora allows to resell any non-defaulted loan investment and the buyers have available all the resources to make the informed decision – not only the information from the loan application but also pre-existing course of the loan performance: payment plan, date and amount of each payments, remainders sent, missed payments etc. The liquidity on the secondary market is sufficiently high and the transaction costs represent 1.5 % of the principal amount traded, which allows investor to liquidate their positions quite comfortably, if needed.
Default risk aside, the main danger in the P2P lending represents the operator risk. Indeed, there were already some bankruptcies in the past and this risk should be borne in mind when considering investments in this new and still rather experimental product. At Bondora, the loans are legally binding contracts signed between lender and borrower (or between lenders in case of reselling).32 The existence of the claims are not entirely dependent on the existence of the market operator.33 The enforceability of a portfolio of a huge amount of tiny loans would be, however, rather questionable.
Data description
The data set obtained from the Bondora Data Export [37] contains 6818 loans provided between 28th February 2009 and 16th April 2014. Since my goal is to build a model predicting the probability of default on a 1-year horizon, only the loans provided between 28th February 2009 and 16th April 2013 were used, 2932 data points in total.
Information available for each loan are quite thorough, include the personal as well as behavioural information about the borrower and cover also the performance of each loan and the recovery process in case the loan defaulted. The complete list of the data set values are summarized in the Table 2.
All the numerical data were normalized using the z-score. All the categorical variables were encoded using the technique of the dummy variables described in Chapter 3. The missing values were replaced by the newly created “N/A” category in case of the categorical variables and by the mean value in case of the numerical variables. No effort has been made to decrease the number of categories in the categorical variables (e.g. to join several categories with similar probability of default into one).
In the alternative approach, the categorical variables were replaced by the respective Weight of Evidence of each category as defined by equation (3.1). My goal was to learn, if and how will the treating of the categorical variables affect the performance of different models.
The binary class variable “1-YR DEFAULT” was calculated, being 1 in cases where the default occurred less than 365 after the loan origination date and 0 in cases when the default occurred later or no default was observed at all. The loan is considered to be in default, when borrower missed the scheduled payment by more than 60 days.
Of the 2932 loans, 656 defaulted by the end of the first year (or 22.37 percent of all loans granted). In total 2 096 352 EUR was lent; the total Exposure at Default for the defaulted loans was 281 946 EUR (or 13.45 percent of the amount). These numbers demonstrate a high risk-exposure in the P2P lending portfolios even when compared with the credit cards delinquency rates. On the other hand, the average recovery rates of the defaulted loans reach 60-70 percent and are noticeably higher than in the credit cards loans portfolios. [8]
| ApplicationSignedHour | n | Hour of signing the loan application. | |
| ApplicationSignedWeekday | n | Weekday of signing the loan application. | |
| VerificationType | c | 3 | Method of application data verification. |
| language_code | c | 3 | Language settings of the borrower. |
| Age | n | Age of the borrower (years). | |
| Gender | c | 2 | Gender of the borrower. |
| credit_score | c | 6 | Payment history (1000-500). |
| CreditGroup | c | 3 | Disposable income (A,B,C). |
| TotalNumDebts | n | Total number of debts. | |
| TotalMaxDebtMonths | n | The longest period when loans were in debt. | |
| AppliedAmount | n | Amount applied. | |
| Interest | n | Maximum interest acceptable for borrower. | |
| LoanDuration | n | The loan term in months. | |
| UseOfLoan | c | 9 | Use of loan as declared by the borrower. |
| ApplicationType | c | 2 | Auction or fixed-interest rate. |
| education_id | c | 5 | Education of the borrower. |
| marital_status_id | c | 5 | Current marital status of the borrower. |
| nr_of_dependants | n | Number of children or other dependants. | |
| employment_status_id | c | 5 | Current employment status. |
| Employment_Duration | n | Years with the current employer. | |
| work_experience | n | Work experience in total (years). | |
| occupation_area | c | 20 | Occupation area, economic sectors. |
| home_ownership | c | 10 | Homeownership status. |
| income_total | n | Total income. | |
| DebtToIncome | n | Debt to income ratio (DTI). | |
| NewLoanMonthlyPayment | n | New loan monthly payment. | |
| AppliedAmountToIncome | n | Applied amount to income, %. | |
| FreeCash | n | Discretionary income after monthly liabilities. | |
| LiabilitiesToIncome | n | Liabilities to income, %. | |
| NewPaymentToIncome | n | New payment to income, %. | |
| NoOfPreviousApplications | n | Number of previous loan applications. | |
| AmountOfPreviousApplications | n | Value of previous loan applications. | |
| NoOfPreviousLoans | n | Number of previous loans approved. | |
| AmountOfPreviousLoans | n | Value of previous loans | |
| PreviousRepayments | n | Previous repayments | |
| PreviousLateFeesPaid | n | Previous late charges paid |
Table 2. List of the data set features. Second column: c = categorical, n = numerical variable. Number of categories with non-zero observations are stated for the categorical variables.
Benchmark model: Logistic regression
Logistic regression as the industry standard for the credit scoring was used to build a benchmark model for the purpose of the performance comparison with the Support vector machines. The backward selection algorithm with the threshold p-value = 0.05 was used to identify the statistically significant features in the data set. The Chi-Square Wald statistics was used as a criterion, which allows for evaluating the contribution of categorical variable as a whole. The following analysis of variables significance is inspired by the approach taken in [5].
I performed 10 independent runs of the backward selection algorithm, each time with the different random training and testing subsets. The resulting models differed, sometimes quite significantly, in the number of variables selected as statistically significant. They were however very similar in terms of the performance measured by the AUC.
Table 3 shows the results of the feature selection process for two different handling of the categorical variables. We can clearly see, that there are 11 explanatory variables that are consistently selected on every run while the significance of some others seems to be unreliable and data-dependent. They may survive the elimination process on some of the random data subsets but drop out as insignificant on the other ones.
Another remarkable conclusion is that the process of handling the categorical variables HAS an effect on the variable selection process. Although the results are similar, they are not same – there are couple of variables in the woeised dataset, that does not appear in the dummy variables dataset (like ApplicationSignedHour). This may be caused by the fact, that MLE algorithm used in Matlab for the logistic regression parameters estimate had some issues with the dummy dataset. Sometimes, it was not able to reach results during a satisfactory number of iterations. Woeised dataset did not exhibit such troubles and the parameters estimation was fast and efficient.
| Dummy variables | WOEisation | ||||
| Variable | # | Rank | Variable | # | Rank |
| credit_score | 10 | 1.00 | credit_score | 10 | 1.00 |
| Interest | 10 | 2.00 | Interest | 10 | 2.00 |
| PreviousRepayments | 10 | 4.30 | ApplicationSignedHour | 10 | 3.90 |
| Age | 10 | 4.70 | PreviousRepayments | 10 | 4.80 |
| AmountOfPreviousLoans | 10 | 4.90 | home_ownership_type | 10 | 5.00 |
| marital_status_id | 10 | 6.50 | AmountOfPreviousLoans | 10 | 5.50 |
| language_code | 10 | 6.60 | language_code | 10 | 5.80 |
| NewLoanMonthlyPayment | 10 | 9.43 | marital_status_id | 10 | 8.90 |
| AppliedAmount | 10 | 11.80 | Age | 10 | 9.90 |
| nr_of_dependants | 10 | 12.70 | occupation_area | 10 | 10.70 |
| occupation_area | 10 | 13.00 | employment_status | 10 | 11.00 |
| employment_status | 9 | 11.89 | NewPaymentToIncome | 9 | 11.11 |
| VerificationType | 8 | 7.69 | NewLoanMonthlyPayment | 9 | 12.22 |
| NewPaymentToIncome | 8 | 11.25 | ApplicationSignedWeekday | 7 | 15.00 |
| ApplicationType | 7 | 14.43 | AppliedAmount | 6 | 13.83 |
| UseOfLoan | 6 | 11.50 | ApplicationType | 5 | 14.80 |
| income_total | 5 | 15.40 | nr_of_dependants | 4 | 14.25 |
| Employment_Duration | 4 | 17.50 | LiabilitiesToIncome | 2 | 14.50 |
| home_ownership_type | 3 | 10.00 | UseOfLoan | 2 | 15.50 |
| FreeCash | 3 | 15.00 | education_id | 1 | 12.00 |
Table 3. Summary of the variables selected by the Backward selection algorithm with the threshold p-value = 0.05 for two different categorical variables handling. The column # presents number of independent runs in which the variable was selected as statistically significant. The column Rank shows the average rank of each variables when sorted by it’s p-value in each model.
On average, 15 explanatory variables stayed in the model after the feature selection process. There were minimum 13 and maximum 17 variables in the model on the 0.05 significance level.
All the variables that occurred in the absolute majority of trials were then used to build a final logistic regression model. The detail description, analysis and maximum likelihood estimates are given in Appendix A.
SVM with Linear kernel
Unlike logistic regression, there are no standardized and generally applicable procedures to judge the statistical significance of the explanatory variables and to select the most important ones. The techniques used all over the relevant literature are rather heuristics or ad-hoc ideas that could not be relied upon in general.34
I have extensively experimented with the procedure described in section Backward selection with the AUC as decision criterion, using the chi-square statistic test to distinguish the real performance improvement from the differences caused by the pure chance.
Unfortunately, the feature selection was very unstable. Except the most significant features (credit_score, Interest), the selected final models seemed to be affected more by random fluctuations and no clear pattern could be identified. This is true for SVM with linear kernel as well as with the Gaussian kernel. After many attempts, I have discarded this approach as unreliable and abandoned the idea.
The main challenge arises from the fact, that there are no formal statistical tests similar to the Wald statistics used in Logistic Regression which could be used to evaluate the contribution of the given variable to the performance of the whole model in case of Support Vector Machines. Indeed, there are some proposals, in the literature, but nothing that could be compared in terms of formal definition and theoretical background.
Other quantitative approaches (like F-Score mentioned in here) can play only subsidiary role in the feature selection process due to the strong assumptions they depend on (e.g. the independence of features).
Guyon in [27] does propose some methods for the feature selection, namely the square of the weights from the hyperplane generated by the support vector machines,  . Although theoretically justified, this can be used only as the ordinal criterion to rank the explanatory variables. It does not tell us, whether the specific value of the square of the weight is high enough to be considered as statistically significant. Another difficulty arises with the categorical variables in the dummy approach – how should be the square of weights relevant to the categorical variable aggregated so that it can be compared with one single number obtained from the numerical variable?
. Although theoretically justified, this can be used only as the ordinal criterion to rank the explanatory variables. It does not tell us, whether the specific value of the square of the weight is high enough to be considered as statistically significant. Another difficulty arises with the categorical variables in the dummy approach – how should be the square of weights relevant to the categorical variable aggregated so that it can be compared with one single number obtained from the numerical variable?
Bellotti in [5] cunningly bypasses these problems:
We set a threshold of 0.1 [for weights on explanatory variable] and all features with weights greater than this will be selected as significant features. This threshold level is chosen since we found it yields approximately the same number of features as the LR method.
The quotation emphasizes the greatest obstacle for the wider application of the support vector machines for credit scoring. As Bellotti&Crook wrote in the introduction of their work [5]:
Financial institutions are primarily interested in determining which consumers are more likely to default on loans. However, they are also interested in knowing which characteristics of a consumer are most likely to affect their likelihood to default. (…) This information allows credit modellers to stress test their predictions.
So our approach to feature selection could be as follows:
- Choose the statistically significant features using Logistic regression and the formal statistical tests (e.g. Wald statistics).
- Train support vector machines using these features.
Since the goal of my thesis is to compare performance between SVM and LR, this approach may be deemed reasonable. As a consequence, SVM cannot be regarded as a stand-alone method in such a framework.
Genetic algorithm for feature selection problem was proven to be superior to the above mentioned approaches [36]. Genetic algorithm approach, on the other hand, brings up the black box problem. The resulting models may be better and more robust in terms of the discriminative power. But with its inability to quantify the contribution of each variable, one cannot expect that such framework could be adopted by conservative and highly regulated financial institutions, no matter how perfect the resulting models would be, compared to traditional ones. For this exactly reason, I did not consider genetic algorithm for feature selection as a viable option for this purpose.
Optimal cost parameter search
Support vector machines bring another hitch to get over – before the actual training begins, the optimal cost parameter C needs to be found. I have used the technique described in the section Grid search.
The values of  from the interval
from the interval  were examined. Since the default value recommended by the LIBSVM manual [9],
were examined. Since the default value recommended by the LIBSVM manual [9],  , was among the best performing possibilities, I have selected that value as the optimal one to proceed.
, was among the best performing possibilities, I have selected that value as the optimal one to proceed.
One very important conclusion regarding the categorical variables follows from the optimal cost parameter search. While the optimal  was clear and easy to find in the case of “woeised” data set, the exact opposite is true in the case of “dummy variables” data set.
was clear and easy to find in the case of “woeised” data set, the exact opposite is true in the case of “dummy variables” data set.
In the latter case, the performance exhibited a chaotic behaviour. No matter how fine the division of the possible values was, even the slightest change of led to the great and unpredictable changes in the observed AUC on the testing sample. Such phenomenon is rather disturbing and indicates a lower-than-expected robustness of the linear SVM in combination with the dummy variables used to express categorical values.
Another issue arose with values  and was common for both the data sets. The time needed for the SVM algorithm to find an optimal hyperplane rises exponentially for the higher values of (see Figure 7). The increased computational demandingness does not translate into higher performance, though. Based on the numerous experiments carried out for the sake of this thesis, I cannot recommend using values higher than
and was common for both the data sets. The time needed for the SVM algorithm to find an optimal hyperplane rises exponentially for the higher values of (see Figure 7). The increased computational demandingness does not translate into higher performance, though. Based on the numerous experiments carried out for the sake of this thesis, I cannot recommend using values higher than  , as they lead to unbearably long training times even on smaller data set comprising of just couple of hundreds of data points.
, as they lead to unbearably long training times even on smaller data set comprising of just couple of hundreds of data points.
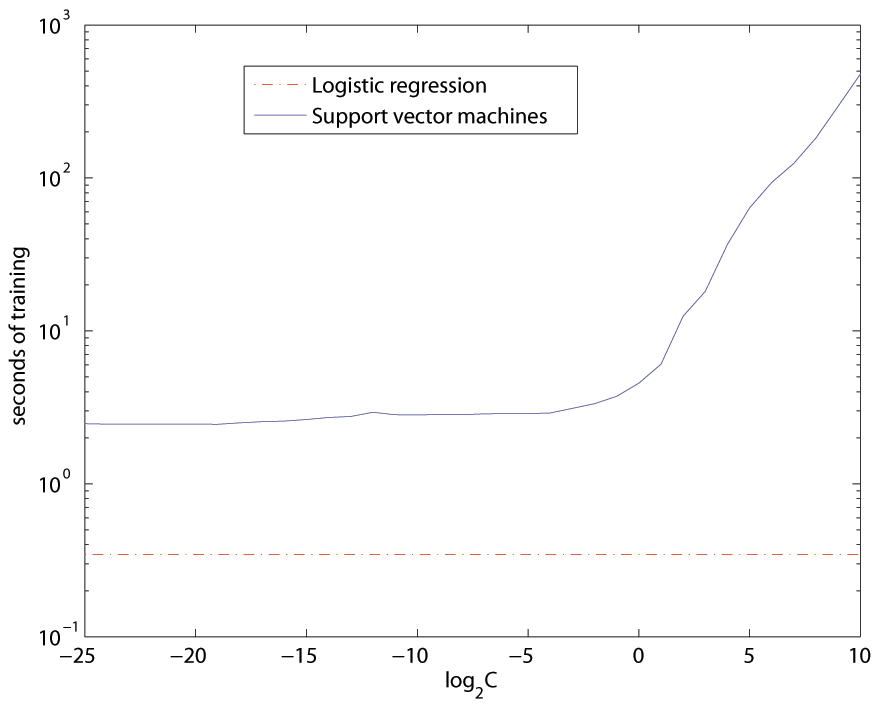 . The time on the y-axis is in the logarithmic scale. For values
. The time on the y-axis is in the logarithmic scale. For values  , the dependence becomes roughly exponential and the training time rises quickly to the unbearable values. The training time of the logistic regression on the very data set is shown for comparison (t = 0.347 seconds).
, the dependence becomes roughly exponential and the training time rises quickly to the unbearable values. The training time of the logistic regression on the very data set is shown for comparison (t = 0.347 seconds).SVM with Gaussian kernel
Radial basis function as defined in (2.38) is probably the most used non-linear kernel in connection with the support vector machines. The Gaussian kernel maps the data set from the original space with  dimensions to the feature space with infinite number of dimensions. Despite this fact, it has only one parameter. Thus, RBF unites the sensible computational costs with the robustness and flexibility of the separating hyperplane shapes.
dimensions to the feature space with infinite number of dimensions. Despite this fact, it has only one parameter. Thus, RBF unites the sensible computational costs with the robustness and flexibility of the separating hyperplane shapes.
Together, there are 2 parameters to be found: cost parameter and shape parameter  . The recommended 2-D grid search technique as described here and depicted at Figure 6 was used for this task.
. The recommended 2-D grid search technique as described here and depicted at Figure 6 was used for this task.
Once again, the stability and robustness of the search process was by far higher in the case of the woeised data set.
The optimal parameters  and
and  were found to maximize the AUC on the test sample.
were found to maximize the AUC on the test sample.
Model results
There are three questions I was looking the answer for:
How is the model performance affected by the number of explanatory variables included in the model?
Does the feature selection process bring some added value or will the performance of the unrestricted model be satisfactory enough to skip this time-consuming task with no remorse?
How is the model performance affected by the way the categorical variables are treated?
The following steps were taken to ascertain the answers to these questions and to deduce some conclusions: With the statistically significant variables identified in the previous section, I started with the most important one (credit_score). Gradually, one by one, other variables were added to the model according to the Table 3. The performance of each models was evaluated using the K-fold cross validation (K = 10) and the respective AUC and its standard deviations were obtained. The performance was then compared with the performance of the unrestricted model.
The results are summarized in Table 4 for the benchmark logistic regression model, Table 5 for SVM with linear kernel and in Table 6 for SVM with gaussian kernel.
| Dummy variables | WOEisation | |||
| Model | AUC | Model | AUC | Diff. |
| credit_score | 0.641 | credit_score | 0.650 | +0.009 * |
| Interest | 0.717 | Interest | 0.722 | +0.006 ** |
| PreviousRepayments | 0.727 | ApplicationSignedHour | 0.735 | +0.008 |
| Age | 0.729 | PreviousRepayments | 0.744 | +0.015 ** |
| AmountOfPreviousLoans | 0.735 | home_ownership_type | 0.753 | +0.018 ** |
| marital_status_id | 0.747 | AmountOfPreviousLoans | 0.758 | +0.011 |
| language_code | 0.750 | language_code | 0.761 | +0.011 |
| NewLoanMonthlyPayment | 0.752 | marital_status_id | 0.765 | +0.013 * |
| AppliedAmount | 0.752 | Age | 0.767 | +0.015 ** |
| nr_of_dependants | 0.754 | occupation_area | 0.770 | +0.016 ** |
| occupation_area | 0.753 | employment_status | 0.772 | +0.019 ** |
| employment_status | 0.755 | NewPaymentToIncome | 0.774 | +0.019 ** |
| VerificationType | 0.760 | NewLoanMonthlyPayment | 0.775 | +0.015 ** |
| NewPaymentToIncome | 0.762 | ApplicationSignedWeekday | 0.775 | +0.014 * |
| ApplicationType | 0.762 | AppliedAmount | 0.777 | +0.015 ** |
| UseOfLoan | 0.760 | ApplicationType | 0.775 | +0.015 ** |
| income_total | 0.761 | nr_of_dependants | 0.776 | +0.015 ** |
| Employment_Duration | 0.762 | LiabilitiesToIncome | 0.775 | +0.014 * |
| home_ownership_type | 0.761 | UseOfLoan | 0.775 | +0.014 ** |
| FreeCash | 0.761 | education_id | 0.774 | +0.014 * |
| Unrestricted | 0.750 | Unrestricted | 0.768 | +0.018 ** |
Table 4. The summary of the performance of logistic regression with respect to the number of variables included in the model. The order of the inclusion was done according to the Table 3, i.e. first row model contains only one variable (credit_score), second row model contains two variables (credit_score and Interest) etc. The column Diff. calculates the difference between AUC of the woeized model against AUC of the model with dummy variables. The difference marked with * is significant at 95 % level, marked with ** is significant at 99 % level. The statistical significance of the difference between the models was tested by the DeLong&DeLong test. [18]
| Dummy variables | WOEisation | |||
| Model | AUC | Model | AUC | Diff. |
| credit_score | 0.627 | credit_score | 0.664 | +0.038 ** |
| Interest | 0.645 | Interest | 0.689 | +0.044 ** |
| PreviousRepayments | 0.644 | ApplicationSignedHour | 0.701 | +0.056 ** |
| Age | 0.683 | PreviousRepayments | 0.701 | +0.017 |
| AmountOfPreviousLoans | 0.707 | home_ownership_type | 0.702 | -0.005 |
| marital_status_id | 0.702 | AmountOfPreviousLoans | 0.729 | +0.026 * |
| language_code | 0.726 | language_code | 0.728 | +0.002 |
| NewLoanMonthlyPayment | 0.726 | marital_status_id | 0.744 | +0.019 * |
| AppliedAmount | 0.730 | Age | 0.748 | +0.018 * |
| nr_of_dependants | 0.729 | occupation_area | 0.750 | +0.021 ** |
| occupation_area | 0.717 | employment_status | 0.755 | +0.039 ** |
| employment_status | 0.725 | NewPaymentToIncome | 0.754 | +0.029 ** |
| VerificationType | 0.730 | NewLoanMonthlyPayment | 0.758 | +0.028 ** |
| NewPaymentToIncome | 0.735 | ApplicationSignedWeekday | 0.758 | +0.023 ** |
| ApplicationType | 0.734 | AppliedAmount | 0.758 | +0.025 ** |
| UseOfLoan | 0.735 | ApplicationType | 0.760 | +0.025 ** |
| income_total | 0.735 | nr_of_dependants | 0.761 | +0.026 ** |
| Employment_Duration | 0.735 | LiabilitiesToIncome | 0.761 | +0.027 ** |
| home_ownership_type | 0.736 | UseOfLoan | 0.762 | +0.026 ** |
| FreeCash | 0.736 | education_id | 0.762 | +0.027 ** |
| Unrestricted | 0.722 | Unrestricted | 0.756 | +0.034 ** |
Table 5. Performance of the support vector machines model with the linear kernel with the cost parameter  . The arranging and meaning of the columns are exactly same as in Table 4.
. The arranging and meaning of the columns are exactly same as in Table 4.
| Dummy variables | WOEisation | |||
| Model | AUC | Model | AUC | Diff. |
| credit_score | 0.584 | credit_score | 0.568 | -0.016 |
| Interest | 0.658 | Interest | 0.615 | -0.044 |
| PreviousRepayments | 0.662 | ApplicationSignedHour | 0.617 | -0.044 |
| Age | 0.659 | PreviousRepayments | 0.669 | +0.010 |
| AmountOfPreviousLoans | 0.677 | home_ownership_type | 0.681 | +0.004 |
| marital_status_id | 0.697 | AmountOfPreviousLoans | 0.703 | +0.006 |
| language_code | 0.710 | language_code | 0.718 | +0.008 |
| NewLoanMonthlyPayment | 0.706 | marital_status_id | 0.717 | +0.012 |
| AppliedAmount | 0.725 | Age | 0.726 | +0.001 |
| nr_of_dependants | 0.730 | occupation_area | 0.755 | +0.025 |
| occupation_area | 0.782 | employment_status | 0.743 | -0.039 * |
| employment_status | 0.791 | NewPaymentToIncome | 0.736 | -0.056 ** |
| VerificationType | 0.803 | NewLoanMonthlyPayment | 0.739 | -0.064 ** |
| NewPaymentToIncome | 0.800 | ApplicationSignedWeekday | 0.729 | -0.071 ** |
| ApplicationType | 0.804 | AppliedAmount | 0.729 | -0.075 ** |
| UseOfLoan | 0.791 | ApplicationType | 0.732 | -0.060 ** |
| income_total | 0.792 | nr_of_dependants | 0.751 | -0.041 * |
| Employment_Duration | 0.794 | LiabilitiesToIncome | 0.755 | -0.039 * |
| home_ownership_type | 0.795 | UseOfLoan | 0.775 | -0.021 |
| FreeCash | 0.796 | education_id | 0.769 | -0.028 |
| Unrestricted | 0.831 | Unrestricted | 0.806 | -0.025 * |
Table 6. Performance of the support vector machines model with the Gaussian kernel with parameters  . The arranging and meaning of the columns are exactly same as in Table 4.
. The arranging and meaning of the columns are exactly same as in Table 4.
The benchmark logistic regression model shows a mild benefit from the woeisation of the categorical variables. It is also clear, that the feature selection may be beneficial for LR, as the performance of the unrestricted model as well as the performance of the model with many explanatory variables underperform the models with fewer variables in both cases.
As already mentioned earlier, I had a big trouble trying to make the linear SVM work, especially on the dummy data set. The performance of the model exhibits a chaotic behaviour, it is extremely sensitive to the value of C parameter. This behaviour made me study the problem further, using the artificially created data sets in the controlled environment. From that it seems to me that the support vector machines with linear kernel might be negatively affected with the unbalanced classes, i.e. the erratic/chaotic behaviour appears, when one class has more prominent representation than the other one. This issue was also discussed in Chapter 4.
Despite the fact, that linear SVM and logistic regression are in principle alike and should lead to similar hyperplanes, the logistic regression has almost always beaten the linear support vector machines in terms of AUC performance. My results contradict the theoretical conclusion coming from the Vapnik–Chervonenkis theory, that the support vector machine gives the best linear classifier. While the theory itself is mathematically proven, it seems that the algorithm does not cope well with the negative frictions and data imbalance in the inputs when applied to the real data sets.
My findings are in agreement with the comparative papers of Baesens et al., [42] and [4], which conclude that, on average, the support vector machines with linear kernel perform slightly worse than logistic regression when applied to the real data sets – although they may perform slightly better in some specific cases.
My experiments with the artificial data also support this conclusion: the maximum likelihood algorithm used for the estimation of the logistic regression parameters gives systematically better results than SVM with linear kernel, in cases when the data show high level of random noise and the classes are imbalanced. The separating hyperplanes provided by the LR was in most cases closer to the ideal solution than the hyperplane generated by the linear support vector machines. The difference descends when the data are well separated (i.e. lower level of random noise) and the classes are equally represented; the superiority of the LR results remains, though.
The linear support vector machines seem to be less affected by the number of explanatory variables included in the model, although the difference is not high to distinguish whether the observed phenomenon is real or caused just by a chance. There is a slight benefit in woeisation of the categorical variables, especially in cases where just a few variables are presented in the model. I have a reason to believe that this is not an artefact; when other categorical variables were used as the only explanatory variable, the woeised version was always doing better than the dummy version.
The true power of support vector machines appears in cases, when the input data exhibit some non-linear behaviour. This is probably the only instance, when SVM can beat the logistic regression as it can produce the separating hyperplane of the shapes that logistic regression simply cannot.
According to my results, this appears to be the case of the Bondora credit scoring data set. The performance of the SVM with RBF was evidently higher than the performance of the benchmark model, with a slightly preference of the dummy variables to the woeised ones.
Again, the AUC increases with the number of explanatory variables and the unrestricted model shows the highest performance among other models. Should it be a general issue, the feature selection process would actually do more harm than good, but I did not perform enough experiments with other data sets to make such a strong conclusion.
My results in the case of non-linear kernel kind of contradict the prevailing conclusions in the literature, namely [5], [42]. Gaussian kernel is seldom reported as being significantly better than the linear kernel and/or the logistic regression, pointing to the logical conclusion that the credit data are usually linear or just mildly non-linear. However, according to Table 6, the superiority of the RBF to the linear classifiers persists without regard to the variables included to the model, the data subset or the time subset of the original inputs and seem to be a real issue in this specific case. Also, my finding is in agreement with the results in [56] where the author used SVM (with linear and non-linear kernel) and LR to evaluate a credit data set from other peer-to-peer lending platform, Lending Club.
| LR | SVM-L | SVM-R | |||||
| Dummy | WOE | Dumy | WOE | Dummy | WOE | ||
| LR | Dummy | +0.015 6.1844 (.0129) |
-0.027 1.9807 (.1593) |
-0.002 1.1057 (.2930) |
+0.069 16.9649 (.0000) |
+0.044 5.4346 (.0197) |
|
| WOE | -0.042 12.109 (.0005) |
-0.017 3.4913 (.0617) |
+0.054 6.2367 (0.0125) |
+0.029 0.8783 (.3487) |
|||
| SVM-L | Dummy | +0.025 4.8055 (.0284) |
+0.096 22.1021 (.0000) |
+0.071 8.2049 (.0042) |
|||
| WOE | +0.071 9.2246 (.0024) |
+0.046 2.5450 (.1160) |
|||||
| SVM-R | Dummy | -0.025 4.3432 (.0372) |
|||||
| WOE | |||||||
Table 7. The statistical tests of the differences in performance among the 6 models considered in this thesis. Each cell contains 3 rows: the difference between AUC of the model specified in the heading minus AUC of the model specified on the left-hand side of the table, the respective  statistics and the p-value. Statistical test from [28] was used.
statistics and the p-value. Statistical test from [28] was used.
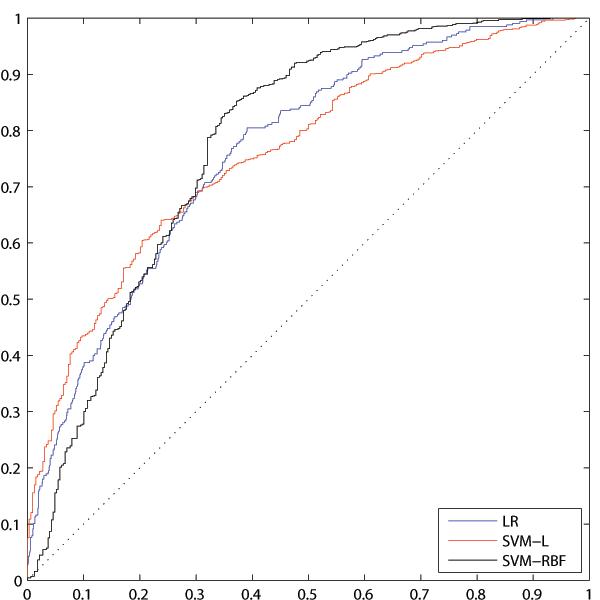
The differences among the models is summarized in Table 7, for each of the 6 model classes, the best performing model with lowest possible variables was selected (15 variables for Logistic regression, 16 variables for linear SVM and unrestricted models for SVM with Gaussian kernel). Two main conclusions can be done according to this table:
- The way how the categorical variables are treated does have influence on the models’ performance, in all cases the difference is statistically significant at 95 % level. The direction of this influence, however, is not stable. One cannot say that woeization brings a performance boost against the dummy variables encoding (or vice versa).
- The SVM-R model with Dummy variables outperforms all the other models at 95 % significance level; apart from woeized LR model it outperforms all of them at 99 % significance level, too.
Quantifying the edge
The mission of this section is to quantify the benefits of using advanced statistical models in investing into the P2P loans. Can the excess performance brought by the now-developed models justify the troubles underwent and time spent building them? Or would be an average investor better off blindly diversifying or counting on the common sense when investing? The backtesting approach was chosen to answer these questions.
Let us focus on three different types of investors:
- RANDOM – Randomly chooses his investments, relying on nothing than diversification effect of a large portfolio of loans and the initial screening process done by the operator of the platform itself.
- NAIVE – The investments are chosen by looking at a couple of simple attributes of the debtor, based on common sense rather than strict mathematical model. This investor will go only for loans, that have: Credit Group A, Credit Score 900-1000, Debt-to-income ratio
 and are willing to pay 22 percent interest, or higher. This investor mimics my own behaviour in the beginning of the platform, when no historical data were available.
and are willing to pay 22 percent interest, or higher. This investor mimics my own behaviour in the beginning of the platform, when no historical data were available. - FORMAL – Investments will be chosen based on the best mathematical model available. In this case it will be the Support vector machines with Gaussian kernel, unrestricted, with the categoricals encoded using the dummy variables. The model is trained for each run using a subset of the data. Then it can invest only in the loans set aside as a test sample. Logistic regression model as a benchmark is used, too.
The backtest was performed using the Monte Carlo simulation approach with 10~000 iterations. The initial investment of 1~000 EUR was allocated in different loans, 10 EUR each. The ROI observed after 1 year of investing and the risk profile of the portfolio (measured as Value at Risk, VaR) were used to evaluate successfulness of the aforementioned strategies. For the sake of the feasibility of this experiment, some simplifying assumptions were made:
- All investments are available for bidding at the beginning and the initial amount can be spread among loans immediately. This was not true when the platform started, but it is a reasonable assumption for the recent months and years.
- The data set is homogeneous enough with respect to the time (i.e. the cohort of loans provided in 2009 has same properties and behaviour as the cohort from 2013). Although this may sound as a strong assumption, my informal analysis does not indicate the presence of sudden changes in the data set and even the default probability was stable throughout the years.
- The investor is in the position of the pure market taker – his investments do not influence the final interest rate of the loan resulting from the auction and have no effect on whether the loan will be provided or fails due to the lack of total money gathered from the investors. Given the low amount per one loan, this assumption is reasonable.
- The defaulted loan is sold on the secondary market right before the default occurs, with the 40 % discount from the current principal. Given the general recovery ratio and my experience, this assumption is also reasonable. The money is then reinvested into another loan according to the respective investment strategy.
- The revenues are reinvested at the end of each month to other loans that satisfy the strategy rules.
- After a year, all cash flows are summed up, the current loans are valued at the remaining principal and the return on investment based on the internal rate of return is calculated.
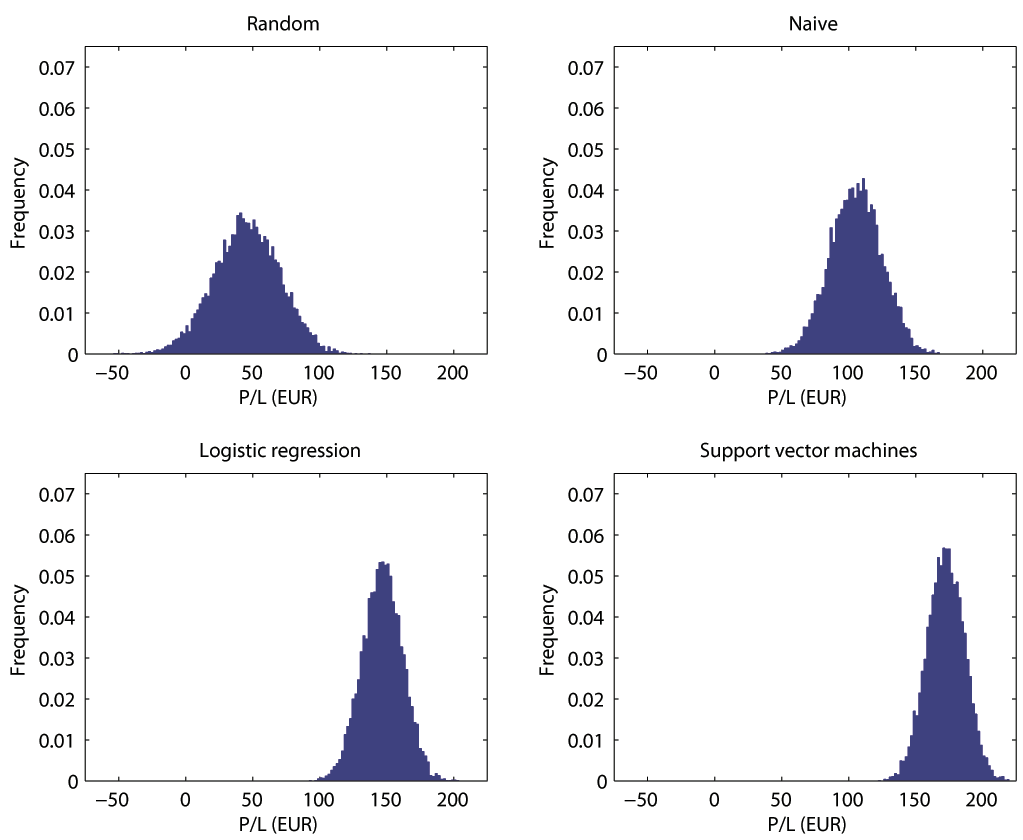
Table 8 shows the results of the backtesting. The amount of loans in portfolio (100 at the beginning, and rising as the revenues are further reinvested) seems to provide a sufficient diversification against a potential loss. The Random strategy is the only one that shows negative VaR(1yr, 1%).
There is a clear pattern in the table: with more sophisticated strategy, there is a higher expected return (profit) and lower risk undertaken. While the Naive strategy outperforms the Random strategy in terms of yield and risk, the formalized approach using either LR model or SVM model tends to bring additional risk-adjusted returns.
Despite the fact that process of development of such model is laborious35 The differences between the strategies are, however, rather small as an absolute value. Therefore, the extra effort could be profitable only to those, who are investing or plan to invest higher amounts of money in absolute terms.
One has to bear in mind, that the Table 8 provides a result of simulations based on simplified assumptions. These numbers can not in any case be used as an extrapolation of future. Personally, I expect that the average return will be decreasing for the next couple of years, as the “market” inside the platform will become more efficient and the operator of the platform will push for higher profits for them, thus wiping off the “early adopters premium”36 which could have been realized at Bondora in the past. Such trends could have been observed at older p2p platforms (like Lending Club) in the previous years, too.
| P/L after 1 year (EUR) | |||||
| Strategy | Mean | St.dev. | q(0.05) | q(0.01) | ROI |
| Random | 45.63 | 24.56 | 5.05 | -12.61 | 4.74 % |
| Naive | 105.50 | 19.13 | 73.98 | 60.49 | 10.97 % |
| LR | 146.77 | 15.04 | 121.60 | 111.29 | 15.25 % |
| SVM-R | 172.41 | 13.97 | 149.17 | 139.60 | 17.91 % |
Table 8. The profit and ROI on 1 year horizon with the initial investment 1 000 EUR spread into 10 EUR loans with different strategies as per the Monte-Carlo simulation with 10 000 independent runs. The standard deviation and the 1-year 5% and 1% quantile as the measures of risk are calculated.
Footnotes
24 In the course of writing this thesis, IsePankur rebranded and renamed to Bondora.com due to the ongoing expansion to other European markets; the original name was not very catchy and easy to pronounce for non-Estonians and this was probably the main reason for rebranding.
25 Open access to the credit data is an industry standard in the peer to peer lending, apart from Bondora some other big platforms like Lending Club, Prosper or Zopa could have been used.
26 The heavily regulated US platforms are restricted only to US citizens, moreover residents only from some US states.
27 Although there are reports, that there is a growing presence of the banks, specialized funds and other “professionals” among the investors on the greatest P2P lending markets and the platform operators are reportedly trying to attract these types of investors to keep the liquidity on their markets. Rather than disruptive competition, the P2P-banks relationship can turn out to be a symbiotic one in the future.
28 Bondora is supervised by the Estonian central bank, ZOPA by the Financial Conduct Authority and the Lending Club and Prosper come under the authority of U.S. Securities and Exchange Commission – to name the 4 largest marketplaces at the moment.
29 Indeed, in United States it is possible to include these investments to one’s IRA account under 401k, make the P2P lending part of the retirement investments and realize the tax advantages on the top of that [41].
30 For example minimum/maximum age, education, DTI ratio and other parameters
31 Recent changes in the system abandoned the auction principle leaving only the fixed-rate loans; my data set nevertheless comes from the time when both these models were available.
32 Estonia is well known for its pioneering attitude to the eGovernment including the electronically concluded contracts and their effective enforcement at the courts.
33 US platforms, on the other hand, take part in the truly securitization schemes where pass-through notes are emitted for each loan. Investors do not (de iure) invest in the loans itself – they buy (and sell) these notes. In all cases, the property of the investors is usually separated from the operator’s assets.
34 See [35] as an example.
35 We are talking about months rather than weeks under amateur investors’ conditions without previous experience in this field.
36 as I use to call it